Chapter 2.0 – ML Data Foundations: The Bridge
How data quality, features, and the training/inference split form the foundation of every ML project. A roadmap for Series 2.
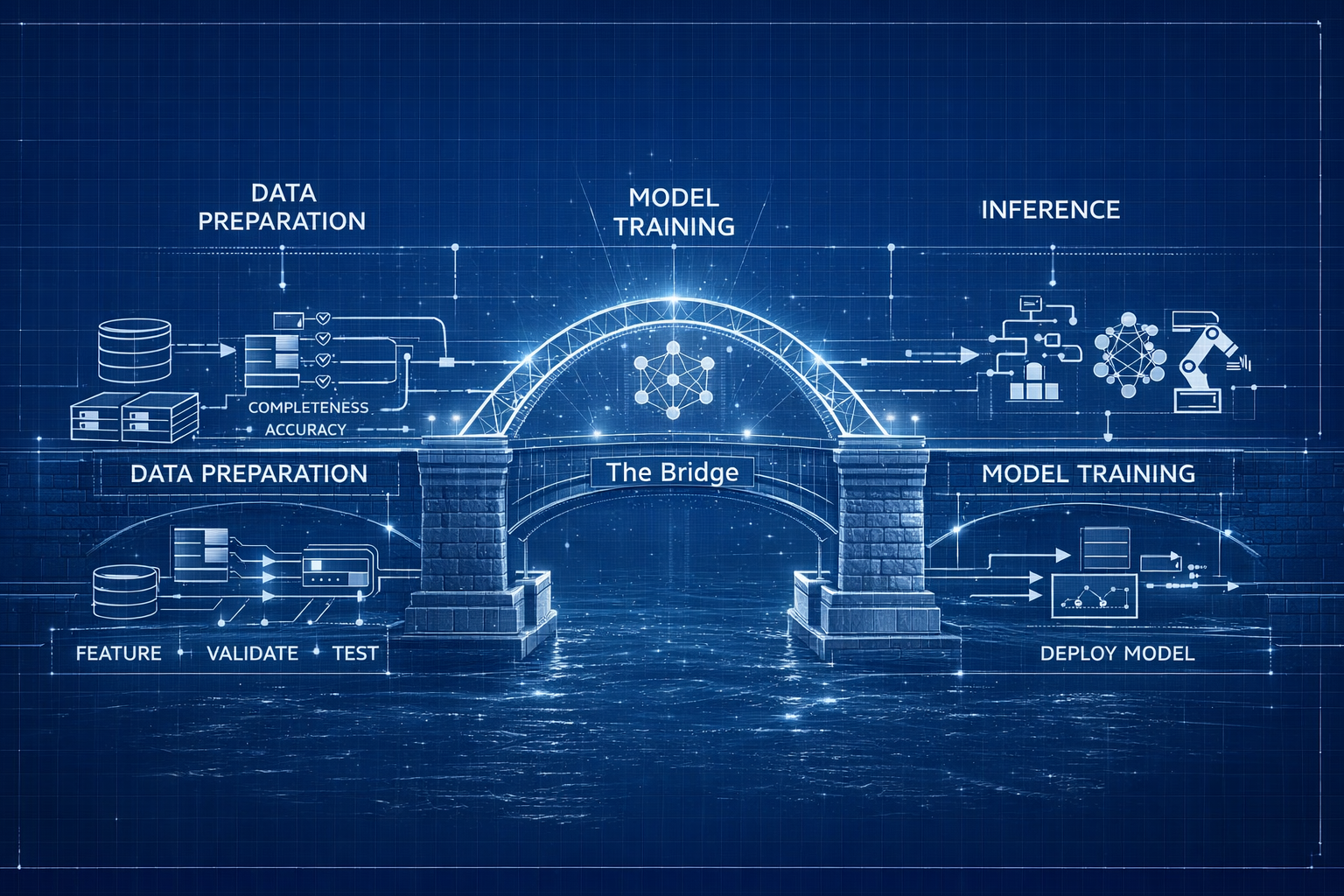
Why This Chapter Exists
When I first started with ML, the data side felt like learning the core building blocks in automation or DevOps—variables, state, pipelines. Each concept was powerful on its own, but it was easy to miss how they all fit together.
Series 2 is about mastering these individual ML data concepts: data quality, features & labels, and the split between training and inference. Think of it as building your toolbox—one essential skill at a time—so you’re ready for any ML project later.
This chapter is a quick bridge: it connects the dots between these core ideas and sets the stage for the deep dives ahead.
How to use this chapter:
Use this as a reference as you work through Series 2. Each section previews a key concept and points you to the chapter where you’ll master it. If you get lost, come back here for the big picture.
The Three Pillars of ML Data (Series 2 Roadmap)
| Data Pillar | Series 2 Chapter & Link |
|---|---|
| Data Quality | 2.1 – Data Quality & Preparation |
| Features & Labels | 2.2 – Features, Labels, and Models |
| Training vs Inference | 2.3 – Training vs Inference |
Refer to this table as you work through Series 2 and want a refresher on any foundational concept.
Why Data Quality Comes First
Key Insight: No amount of algorithmic wizardry can fix bad data. Data quality is the foundation of every ML project.
- What makes data “good” for ML?
- How do you spot and fix data issues before they break your model?
- Why is data preparation 80% of the work?
See Chapter 2.1 for practical techniques and real-world examples.
Features & Labels: The Language of ML
Key Insight: Features are the inputs; labels are the answers. ML is about learning the mapping between them.
- What counts as a feature, and how do you choose them?
- What is a label, and why does it matter?
- How do features and labels shape the model you build?
See Chapter 2.2 for hands-on guidance and examples.
Training vs Inference: Two Worlds, One Model
Key Insight: Training is where the model learns; inference is where it predicts. Mixing them up leads to real-world failures.
- What’s the difference between training and inference?
- Why do you need to separate your data and logic for each?
- How do you avoid common pitfalls?
See Chapter 2.3 for best practices and lessons learned.
What’s Next
This chapter is your launchpad for Series 2. As you read each chapter, refer back here to see how the pieces fit together. By the end, you’ll have a solid foundation for every ML project you tackle.