Chapter 1.2 – How Machines Learn
How machines learn: the core mental shift for automation engineers.
How Machines Actually Learn — The Core Mental Shift
As an engineer, I used to write explicit rules: “If X, then do Y.” Machine learning flips this on its head. Instead of coding rules, you give the system examples—and it learns patterns from data.
If you want a deep dive into the difference between automation and AI/ML, see Chapter 1.1. Here, we’ll focus on what actually happens when a machine learns, and why this shift matters for engineers.
1. From Rules to Learning
In programming and automation, you write the logic:
1
Rules + Input Data → Output
In machine learning, the system learns the logic from data:
1
2
Historical Data + Outcomes → Model
Model + New Input → Prediction
Key Insight: The core of ML is this inversion: models learn patterns from data, not rules. (See Chapter 1.1 for diagrams and a full breakdown.)
Here’s a visual summary of the difference:
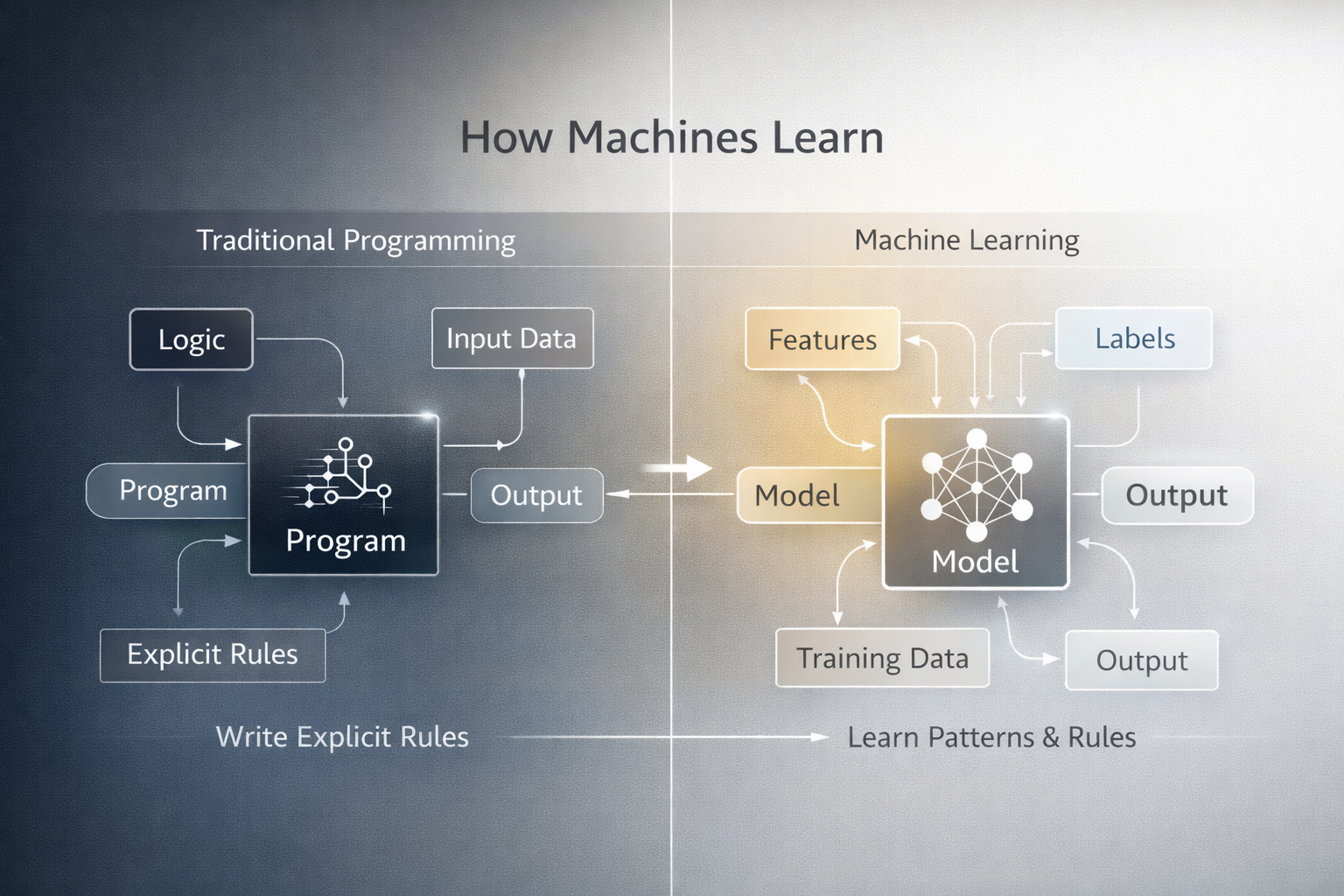
2. Why Rule-Based Systems Stop Scaling
Most organizations start with rule-based automation for change governance:
1
2
3
IF environment == PROD
AND change_type == Infrastructure
THEN manual approval required
Characteristics:
- Rule-based and deterministic
- Easy to audit
- Same treatment for all changes
Limitations:
- Slows down low-risk changes
- High-risk changes may still slip through
- Rules grow endlessly as exceptions are added
- No learning from past outcomes
As platforms mature, teams add more exceptions and conditions:
1
2
3
IF prod AND infra AND resource_count > 5 → approval
IF prod AND infra AND time == peak_hours → approval
IF prod AND app AND config_only → auto-approve
Over time, this leads to:
Simple Rules –> More Conditions –> Complex Decision Trees –> Hard-to-maintain Systems
At this point, the problem is no longer automation—it’s decision complexity. The system becomes fragile and hard to update, and it still can’t learn from new data or adapt to new risks.
3. How Learning Changes the Problem
Instead of asking:
“What rules should we write?”
We ask:
“What can we learn from past changes?”
Each historical change becomes a training example.
4. What Machines Learn From — Training Data
Here’s the shift: machines don’t learn from instructions. They learn from examples.
Each historical change becomes a training record:
1
2
3
4
5
Change Type: Infrastructure
Environment: Production
Resources Modified: 6
Deployment Time: Peak Hours
Outcome: Failed
Thousands of these records = the training dataset.
Warning: Garbage data in = garbage predictions out. The model can only be as good as your historical data.
Features and Labels — Inputs vs Outcomes
To make learning possible, training data is split into two parts.
Features (Inputs)
Features describe what the model can look at.
Examples in our running scenario:
- Change type (IaC / App / Config)
- Files modified
- Resource count
- Environment
- Deployment time
- Historical failure rate
Features answer:
“What information is relevant for decision-making?”
Labels (Outcomes)
Labels represent what we want the model to learn or predict.
Examples:
- Successful
- Rolled back
- Incident caused
- Risk category (Low / Medium / High)
Labels answer:
“What is the expected outcome?”
Principle: Learning happens by correlating features with labels.
What “Learning” Really Means Internally
Learning does not mean the system understands intent.
It means:
- Finding statistical patterns
- Estimating likelihoods
- Generalizing from examples
Example output:
1
2
Probability of failure: 72%
Risk category: High
Key Difference: Learning outcome is probabilistic, not deterministic.
What Actually Changes When a Machine Learns
What actually changes: internal parameters (think: adjustable weights).
1
Predict → Compare with reality → Measure error → Adjust weights → Repeat
This happens thousands of times until:
- Good predictions get reinforced
- Bad predictions get penalized
- The model learns relationships (not rules)
It’s pattern matching, not rule storage.
flowchart LR
A[Training Data<br/>Features + Labels] --> B[Initialize Model<br/>Random Weights]
B --> C[Make Prediction]
C --> D{Compare Prediction<br/>vs Actual Label}
D --> E[Calculate Error]
E --> F[Adjust Weights<br/>Reduce Error]
F -.->|After Many Iterations| G[Trained Model]
style A fill:#e3f2fd,stroke:#1976d2,stroke-width:2px
style B fill:#fff3e0,stroke:#f57c00,stroke-width:2px
style C fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
style D fill:#f3e5f5,stroke:#7b1fa2,stroke-width:2px
style E fill:#ffebee,stroke:#d32f2f,stroke-width:2px
style F fill:#fff3e0,stroke:#f57c00,stroke-width:2px
style G fill:#e8f5e9,stroke:#388e3c,stroke-width:2px
5. Running Example — Deployment Risk Assessment
Imagine a system that predicts the risk of a deployment request (like code or infrastructure changes) before it happens. By analyzing details such as change type, environment, resource count, timing, and team, an ML model can flag high-risk deployments and suggest actions—helping teams make safer, faster decisions. This scenario will be used throughout the series to illustrate key AI/ML concepts in a context familiar to DevOps and platform engineers.
This example is intentionally chosen because it is:
- Familiar to DevOps and platform engineers
- Rich enough to evolve across AI concepts
- Architecturally realistic
flowchart LR
subgraph input["Input: Deployment Request"]
I1[Change Type: IaC]
I2[Environment: Prod]
I3[Resources: 6]
I4[Time: Peak Hours]
I5[Team: Platform]
end
subgraph model["ML Model"]
M[Risk Prediction<br/>Model]
end
subgraph output["Output: Risk Assessment"]
O1[Risk Level: High]
O2[Confidence: 87%]
O3[Recommendation:<br/>Manual Review]
end
input --> model
model --> output
style input fill:#e3f2fd,stroke:#1976d2,stroke-width:2px
style model fill:#fff3e0,stroke:#f57c00,stroke-width:2px
style output fill:#e8f5e9,stroke:#388e3c,stroke-width:2px
style I1 fill:#e3f2fd,stroke:#1976d2,stroke-width:1px
style I2 fill:#e3f2fd,stroke:#1976d2,stroke-width:1px
style I3 fill:#e3f2fd,stroke:#1976d2,stroke-width:1px
style I4 fill:#e3f2fd,stroke:#1976d2,stroke-width:1px
style I5 fill:#e3f2fd,stroke:#1976d2,stroke-width:1px
style O1 fill:#e8f5e9,stroke:#388e3c,stroke-width:1px
style O2 fill:#e8f5e9,stroke:#388e3c,stroke-width:1px
style O3 fill:#e8f5e9,stroke:#388e3c,stroke-width:1px
6. Terraform vs Machine Learning — Architect’s Mental Model
If you write Terraform, this comparison helped me a lot:
Terraform:
1
Variables → Plan → Apply → Infrastructure
Logic is in your code. Output is deterministic.
Machine Learning:
1
Training Data → Model → Prediction → Decision
Logic is learned from data. Output is probabilistic.
| Terraform | Machine Learning |
|---|---|
| Variables | Features |
| Desired state | Labels |
| Plan | Model |
| Apply | Prediction |
Same mental model, different execution.
7. Example — Predictive Auto-Scaling
Rule-Based Scaling
1
2
IF CPU > 70% for 5 minutes
THEN scale out
Learning-Based Scaling
Based on:
- Historical traffic
- Time-of-day patterns
- Deployment events
Predict required capacity before load spikes
Tip: Past behavior informs future decisions
8. What Machines Do NOT Learn
Let’s be clear about limitations (because the AI hype skips this part):
Machines do NOT:
- Understand business intent or context
- Self-correct without feedback
- Replace human accountability
Warning: ML do amplify whatever’s in your data—including bias and bad patterns.
9. Why This Matters for Architects
When you’re designing platforms, understanding how machines learn changes how you think about:
- Approval workflows (dynamic vs fixed)
- Risk assessment (patterns vs rules)
- Audit trails (probabilistic outputs need different governance)
Architect’s Question: Which decisions need rules, and which need learning?
Best platforms? They use both strategically.
10. Formal Definitions (Reference Only)
While the explanations above focus on practical understanding, here are three foundational definitions from the field:
Practical Definition: Machine Learning is the science (and art) of programming computers so they can learn from data.
Academic Definition (Arthur Samuel, 1959): Machine Learning is the field of study that gives computers the ability to learn without being explicitly programmed.
Engineering Definition (Tom Mitchell, 1997): A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
In our running example:
- Experience (E): Historical deployment records
- Task (T): Predict deployment risk
- Performance (P): Accuracy of risk predictions
These definitions complement the practical explanations—you don’t need to memorize them, but they ground the concepts in formal terms.
What I Wish I Knew Earlier
Practitioner’s Lessons:
- Learning replaces rules with patterns
- Training data drives model behavior
- Features describe inputs, labels define outcomes
- ML decisions are probabilistic
- Automation and ML are complementary
What’s Next — Types of Machine Learning
➡ Series 1 – Chapter 1.3: Types of Machine Learning
In the next chapter, we’ll explore:
- Supervised learning (labeled data)
- Unsupervised learning (finding patterns)
- Semi-supervised learning (hybrid approach)
- Reinforcement learning (trial and error)
Architectural Question: How do you decide which type of machine learning is best for a given problem, and what are the risks of choosing the wrong approach?
Now that you understand how machines learn from data, the next step is choosing the right learning approach for your use case.