Chapter 4.1 – Why Deep Learning Exists
Why deep learning emerged, what problems it solves, and when engineers should actually use it.
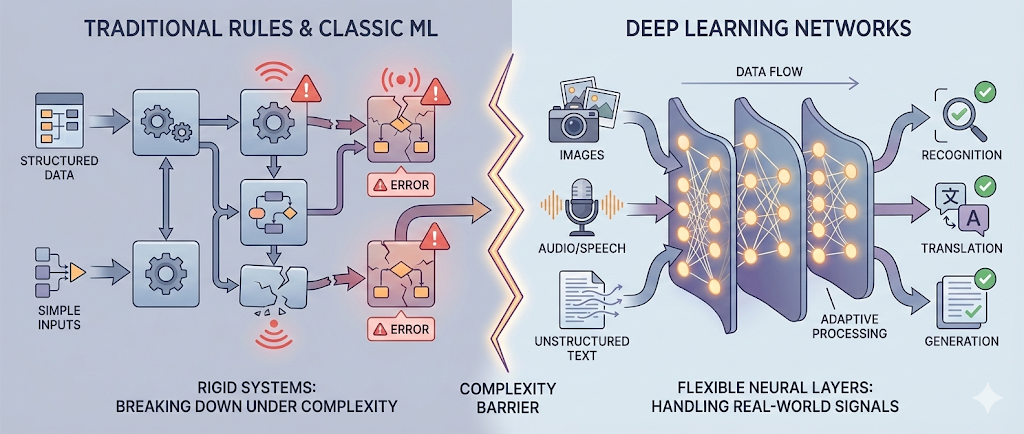
Why Deep Learning Exists
When I first heard deep learning, I honestly thought it just meant “bigger machine learning models with more data.”
But the more I worked through real problems — logs, text, telemetry, messy operational signals — the more I realized something deeper was happening.
Some problems simply refuse to be solved by:
- Rules
- Thresholds
- Feature engineering
- Even well-tuned ML models
That wall is exactly why deep learning exists.
Deep learning wasn’t invented because traditional ML failed — it emerged because some problems are fundamentally too complex to be expressed as rules or handcrafted features.
In this chapter, I want to capture:
- What limits I personally hit when correlating with traditional ML
- What kinds of problems finally made deep learning “click”
- When engineers should (and shouldn’t) actually reach for it
What Is Deep Learning?
Textbook definition: deep learning uses neural networks with many layers to learn complex patterns directly from raw data.
What that meant to me in practice was something simpler:
Instead of me trying to define features up front, the model learns the representations itself.
That shift alone felt huge.
Instead of:
Engineer defines features → model learns weights
It becomes:
Model learns features → model learns weights
Think of it like an automation pipeline — but instead of rules at each stage, every stage learns its own transformations from data.
Engineer’s Insight: Deep learning feels like an automation pipeline that rewrites itself while it’s running.
The Limits of Traditional Machine Learning
Building on what I understood earlier, traditional ML works brilliantly when:
- Data is structured
- Features are known
- Patterns are relatively stable
But many real-world systems — especially in ops, platforms, and applications — don’t look like that. Mine certainly didn’t.
1. Feature Engineering Becomes the Bottleneck
In classical ML, humans must decide:
- Which signals matter
- How to represent them numerically
- Which transformations improve predictions
This works great for metrics tables and clean datasets — but completely breaks down for:
- Logs
- Free text
- Images
- Audio
- Traces
- Graphs
I found myself staring at raw data thinking, “I don’t even know what the right features should be here.”
When humans must define the features, learning speed becomes bounded by human imagination — not data.
In ops terms: it felt like trying to monitor a distributed system by manually writing alert rules for every failure mode. You’ll always be behind reality.
2. Rules and Shallow Models Don’t Scale with Complexity
Traditional ML models (linear models, trees, shallow networks) work well when:
- Relationships are simple
- Interactions are limited
- Data distributions are stable
But modern systems are:
- Nonlinear
- High-dimensional
- Dynamic
- Noisy
As complexity grows, rule systems become brittle and ML pipelines become fragile.
Engineer’s Insight: This feels exactly like maintaining giant shell scripts for complex workflows. At some scale, the logic collapses under its own weight.
3. Representation Is the Real Problem
This took me a while to internalize.
Most hard problems aren’t about prediction — they’re about representation.
Examples:
- What is a “face” in pixel space?
- What is “intent” in free-form text?
- What is “anomaly” in millions of log lines?
Traditional ML assumes humans can define these representations. Deep learning exists because often… we can’t.
What Problems Is Deep Learning Designed For?
Once I saw deep learning as a representtion learner, its use cases suddenly made sense.
Deep learning shines when:
- Inputs are unstructured
- Patterns are hierarchical
- Signals are hidden
- Labels are noisy or scarce
- Relationships are nonlinear
Let’s look at the major classes.
🖼️ Images & Video
Problems like:
- Face recognition
- Object detection
- Medical imaging
- Defect inspection
Here, raw pixels don’t map cleanly to concepts. Deep learning learns edges → shapes → objects → meaning.
🗣️ Text & Language
Problems like:
- Search relevance
- Chatbots
- Log summarization
- Ticket classification
Language is ambiguous, contextual, and symbolic — perfect territory for models that learn representations instead of rules.
🔊 Speech & Audio
Problems like:
- Speech recognition
- Speaker identification
- Event detection
Sound waves are continuous signals — deep learning learns structure humans never could manually design.
📊 High-Dimensional, Noisy Operational Data
In ops and platforms:
- Logs
- Metrics
- Traces
- Telemetry
- Events
These datasets are:
- Massive
- Messy
- Constantly changing
Automation Analogy: Traditional monitoring feels like grep. Deep learning feels like the system learning what “bad” looks like — even when you can’t describe it.
Why Traditional ML Isn’t Enough for These Problems
To connect the dots further, let’s compare the two approaches:
| Traditional ML | Deep Learning |
|---|---|
| Manual feature engineering | Automatic feature learning |
| Works best on structured data | Excels on unstructured data |
| Shallow representations | Deep hierarchical representations |
| Easier to interpret | Higher accuracy at scale |
| Limited by human-designed features | Learns from raw data |
The key shift:
Traditional ML learns patterns over human-designed features.
Deep learning learns the features themselves.
Once this clicked for me, a lot of things suddenly made sense.
Why Deep Learning Works (Conceptually)
Deep learning works because:
- It stacks simple computational units
- Each layer learns a more abstract representation
- Error feedback tunes the entire stack
Instead of humans saying:
“This pixel pattern looks like an edge.”
The network learns: Pixels → edges → shapes → objects → meaning
This layered abstraction mirrors:
- Biological perception
- Software architecture
- Infrastructure layering
Engineer’s Insight: Deep learning looks a lot like infrastructure design. Each layer abstracts complexity so the layer above can operate at a higher level.
We’ll unpack how this actually works in the next chapter.
When Should Engineers Consider Deep Learning?
Summing up my experience so far, I’d reach for deep learning when:
- ✅ Data is large
- ✅ Data is unstructured
- ✅ Features are unknown or expensive to engineer
- ✅ Accuracy matters more than explainability
- ✅ The system must improve continuously
Examples:
- Anomaly detection in logs
- Fraud detection
- NLP-driven ticket routing
- Vision-based inspection
- Speech-to-text systems
When NOT to Use Deep Learning
Pitfall: Don’t use deep learning just because it’s trendy.
In line with the lessons from previous sections, avoid deep learning when:
- Data is small
- The problem is simple and structured
- Interpretability is critical
- Latency or cost budgets are tight
- A rule or classic ML model solves it cleanly
Engineer’s Insight: Sometimes a cron job beats a neural net. Use the simplest system that works — not the most impressive one.
Common Myths
These were a few things I personally believed early on — and had to unlearn:
- ❌ “You always need massive datasets” → Transfer learning exists
- ❌ “It’s all black magic” → It’s math + optimization + feedback
- ❌ “It replaces engineers” → It requires better engineers
- ❌ “It eliminates rules” → It shifts rules into data pipelines
Deep learning doesn’t remove complexity — it relocates it into training workflows, monitoring, governance, and infrastructure.
What I Wish I Knew Earlier
Key Takeaways:
- Deep learning exists because feature engineering and rules don’t scale
- It excels at unstructured, complex, noisy data
- It learns representations, not just rules
- It’s powerful—but not always the right tool for the job
- Deep learning isn’t just smarter automation—it’s automation that learns
What’s Next?
➡ Series 4 – Chapter 4.2: Neural Networks Explained Like Infrastructure
In the next chapter, we’ll explore:
- Neurons as compute units
- Layers as pipelines
- Weights as configuration
- Backpropagation as feedback loops
Architectural Question: How do the core building blocks of neural networks map to infrastructure and automation concepts, and what can engineers learn from these parallels?
We’ve covered why deep learning exists and what makes it different. Next, we’ll break down neural networks in a way that’s intuitive for infrastructure engineers.